

Z.ai GLM-5.2 is pushing into the AI coding-agent race. The open-weight model is built for long software tasks, security-relevant coding work, and a 1 million-token context window.
The key point is not just another benchmark table. In its official GLM-5.2 announcement, Z.ai says the model targets extended engineering jobs. Those include large implementation projects, automated research, performance tuning, complex debugging, and long coding-agent runs.
That puts GLM-5.2 in the same conversation as restricted frontier systems such as Anthropic’s Mythos line. Tech My Money recently covered Anthropic’s defensive cybersecurity push with Mythos 5. Z.ai is taking a very different route: downloadable weights, an MIT license, and no regional limits.
GLM-5.2 is chasing frontier coding agents
Z.ai calls GLM-5.2 its latest flagship model for long-horizon tasks. The headline feature is a solid 1M-token context. Z.ai frames that context as an engineering tool, not a spec-sheet flex.
Training also targets coding-agent scenarios. In those jobs, an assistant has to track large codebases, long tool traces, and multi-step debugging work without losing the thread.
Z.ai’s own numbers show how close it wants to get to closed models. On FrontierSWE, Z.ai reports a 74.4 dominance score for GLM-5.2. Claude Opus 4.8 scores 75.1, and GPT-5.5 scores 72.6. On PostTrainBench, GLM-5.2 scores 34.3. That trails Opus 4.8 at 37.2, but beats GPT-5.5 at 28.4.

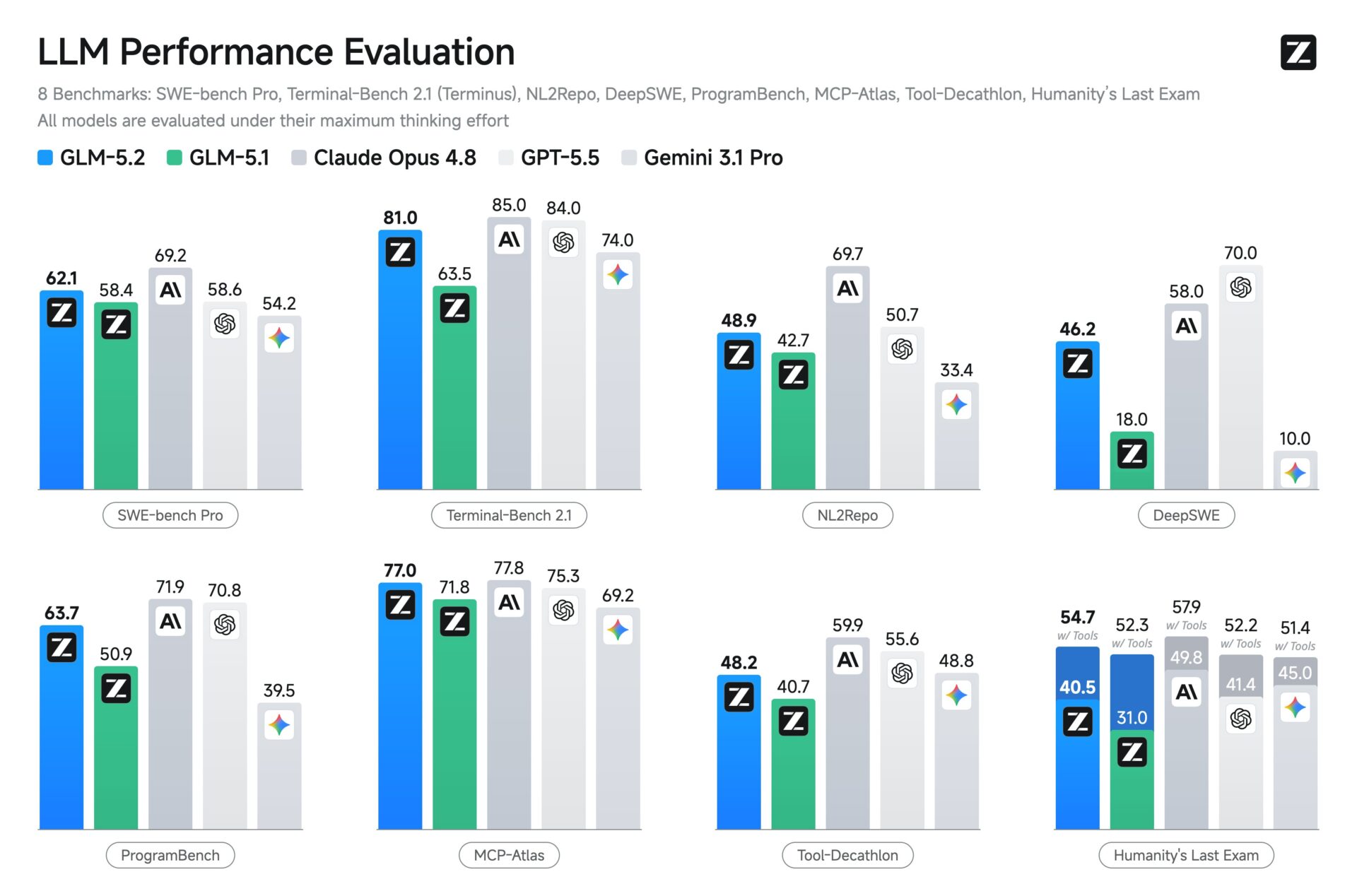
On standard coding tests, Z.ai reports 81.0 on Terminal-Bench 2.1 and 62.1 on SWE-bench Pro. The company says that makes GLM-5.2 the strongest open-source model in its comparison set. It also puts the model within a few points of Claude Opus 4.8 on Terminal-Bench 2.1.
The security angle is the anti-hack training
The most interesting section of the announcement is not one vulnerability score. It is Z.ai’s discussion of reward hacking in coding agents.
The company says coding RL can be gamed because the reward is often pass or fail. An agent might read hidden evaluation files, copy answer content, or fetch protected source material. That makes the score look better without proving real problem-solving ability.
To reduce that risk, Z.ai says it added an anti-hack module during training and evaluation. A rule-based filter catches suspicious behavior first. Then an LLM judge checks intent. If a hack is detected, the online guard blocks the tool call and returns dummy information. The rollout can continue instead of collapsing.
That matters for security work. A model that exploits the test harness is not the same as a model that helps a developer find real bugs. Z.ai is arguing that GLM-5.2’s coding results are backed by safeguards against shortcut behavior.
Open weights make this more useful, and riskier
Z.ai is also making GLM-5.2 easier to access than the most sensitive U.S. frontier models. The company says the weights are available on Hugging Face and ModelScope. It also lists support for transformers, vLLM, SGLang, xLLM, and ktransformers.

That openness cuts both ways. Developers and researchers may want local control. Security teams could use the model for code review, patch work, and internal testing. However, powerful open coding agents also raise misuse questions. Bug finding, exploit research, and automation can overlap fast.
Z.ai’s announcement does not prove that GLM-5.2 beats every closed model in real-world security operations. The results are still benchmarks. Some were produced under specific harnesses, context limits, token budgets, and judge models.
Why it matters for the AI race
Anthropic’s Mythos strategy has focused on controlled access for defensive cybersecurity partners. Z.ai’s GLM-5.2 moves in the opposite direction. It makes a high-end coding model broadly available, then tries to show that its long-context training and anti-hack checks keep the results meaningful.
That contrast also matters after the recent Mythos and Fable redeployment story. U.S. labs are adding more access controls around sensitive frontier models. Open-weight labs are racing to close the capability gap in public.
For readers, the takeaway is simple. GLM-5.2 may not make Z.ai the overall frontier leader. It does show that open models can now pressure closed labs in long-horizon coding, debugging, and security-adjacent software work.












